- Dozent/in: Stefan Bensch
- Dozent/in: Robert Schöffel
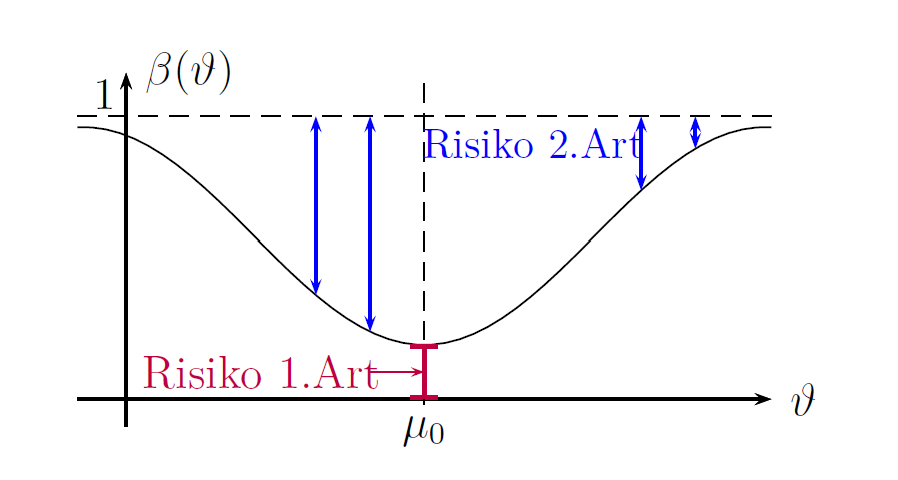
In der induktiven (schließenden, inferentiellen) Statistik werden die
auf der Wahrscheinlichkeitstheorie basierende Verfahren benutzt, um Schlüsse aus Stichproben zu ziehen, wie z.B. bei parametrischen Schätz- und Testverfahren, aber auch bei nichtparametrischen Testproblemen.
- Dozent/in: Wolfgang Bischof

Machine Learning 1
- Donnerstags 09:50 bis 13:10 Uhr, Raum H1.23
- Montags 14:00 bis 15:30 Uhr, Raum C1.13
- Start: 10. Oktober 2024
- Dozent/in: Tobias Rossmann

- Dozent/in: Sebastian Dorn
- Dozent/in: Brigitta Raffai
- Dozent/in: Nicholas Schreck
Dieser Kurs dient der Vorbereitung auf die Wiederholungsklausur im Modul "Deskriptive Statistik und Stochastik"
- Dozent/in: Wolfgang Bischof
- Dozent/in: Sebastian Gil Rodriguez
Die Daten und Modelle, mit denen Data Scientists arbeiten werden immer im Kontext einer Anwendung eingesetzt. Insbesondere ist es notwendig, Daten und auf ihnen basierenden Machine Learning Modelle in eine Applikation einzubetten. Diese Applikation muss den Anforderungen der Nutzer genügen, eine ansprechende und bedienbare Schnittstelle aufweisen. Außerdem ist es notwendig, diese auf einfache Weise auszurollen, zu aktualisieren und zu betreiben.
Anhand einer konkreten Applikation, die Studierende in Zusammenarbeit mit externen Akteuren entwickeln, werden in diesem Kurs die Grundlagen der Applikationsentwicklung, insbesondere Grundlagen der Software-Architektur sowie Scrum als agiler Softwareentwicklungsprozess, geübt. Außerdem liegt ein Fokus auf dem Betrieb von Software in Containern mit Hilfe von Docker und Kubernetes. Dabei arbeiten Studenten der Informatik und aus der Data Science zusammen in einem Team, unterstützen sich gegenseitig mit ihren jeweiligen Fachkenntnissen und interagieren gemeinsam mit den externen Partnern. Die Zusammenarbeit mit externen Partnern erfordert außerdem das Erheben von Anforderungen und regelmäßige Feedbackschleifen.
Lernziele
Nach erfolgreichem Abschluss des Kurses werden die Teilnehmer in der Lage sein:
- den Kontext der Arbeit mit Daten und Modellen und die Bedeutung ihrer Einbettung in eine Anwendung zu beschreiben,
- Verständnis für agile Softwareentwicklungsprozesse, insbesondere Scrum, und wie diese bei der Entwicklung von Data Science-Anwendungen eingesetzt werden können, zu demonstrieren,
- ihre Programmierkenntnissen zur Entwicklung einer Data-Science-Anwendung, die Daten und maschinelle Lernmodelle einbezieht, anzuwenden,
- effektiv mit externen Partnern zusammenzuarbeiten, um Anforderungen zu erfassen, regelmäßiges Feedback einzuholen und die erfolgreiche Bereitstellung der Anwendung sicherzustellen,
- Verständnis der Prinzipien der Softwarearchitektur und ihrer Rolle bei der Entwicklung skalierbarer und wartbarer Data-Science-Anwendungen zu demonstrieren, und
- ihre Fähigkeit, Anwendungen in Docker-Containern zu verpacken und mit Hilfe von Kubernetes zu deployen, warten und zu betreiben, demonstrieren.
Prüfungsleistung
- Erfahrungsbericht (abzugeben in der Gruppe)
- Einzelgespräche
- Peer Assessment
- Quellcode-Analyse
- Dozent/in: Jan-Philipp Steghöfer
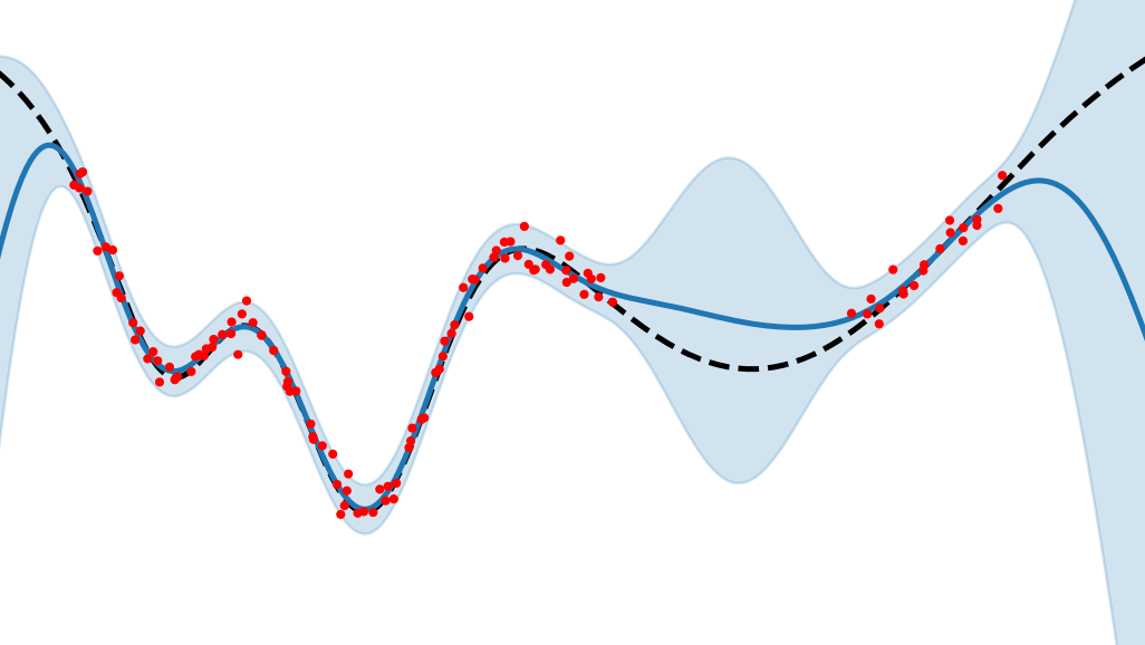
Erlernen des Bayes’schen Wahrscheinlichkeitsbegriffs und daraus abgeleitete Methoden zur statistischen Inferenz und Quantifizierung von Unsicherheiten. Das Modul konzentriert sich sowohl auf die theoretischen Grundlagen als auch auf deren praktische Anwendung und Implementierung mit python.
Inhalt:
- Grundlagen & Bayes'sche Statistik
- Informationstheorie
- Inferenz- und Filtermethoden
- Sequenzielle Daten & State Space Modelle
Vorlesungsbetrieb (Start: 07.10.2024):
- montags, 9:50 - 13:10 Uhr,
- Hörsaal: B3.05
- donnerstags, 11:40 - 13:10 Uhr,
- Raum: P2.02
- Dozent/in: Sebastian Dorn